Platform Overview
OpenAI Compatible Mode
APIYI uses the OpenAI-compatible format. Once it works, switching models only means changing themodel field — everything else stays the same:
For exact model names, pricing, and recommended use cases, see the two dedicated pages under “Choose a Model” below. We don’t list them here to avoid stale information.
Feature Support Scope
Supported
- Chat Completions
- Image / video generation
- Speech transcription (Whisper)
- Embeddings
- Function Calling
- Streaming output (SSE)
- Standard OpenAI params:
temperature,top_p,max_tokens, etc. - Responses endpoint
Not Supported
- Fine-tuning
- Files management
- Organization management
- Billing management
Choose a Model
Not sure which model to use? These two pages are kept up to date with pricing, capability comparisons, and recommendations:Text / Multimodal Models
Capabilities, pricing, and selection guidance for GPT, Claude, Gemini, Grok, DeepSeek, Qwen, Kimi, GLM, and more.
Image / Video Models
Image models like Nano Banana, GPT-image, Seedream, and Flux, plus video models like VEO, Sora, and Wan — pricing and usage.
Basic Information
API Endpoints
- Primary:
https://api.apiyi.com/v1 - Backup:
https://vip.apiyi.com/v1
Authentication
Every request must include your API Key in the header:Request Format
- Content-Type:
application/json - Encoding: UTF-8
- Method:
POSTfor most endpoints
Quick Start
Get an API Key
- Visit the APIYI console and log in
- On the token management page, click “Add” to create an API Key
- Copy the generated key for use in your requests
Get Multi-Language Code Examples
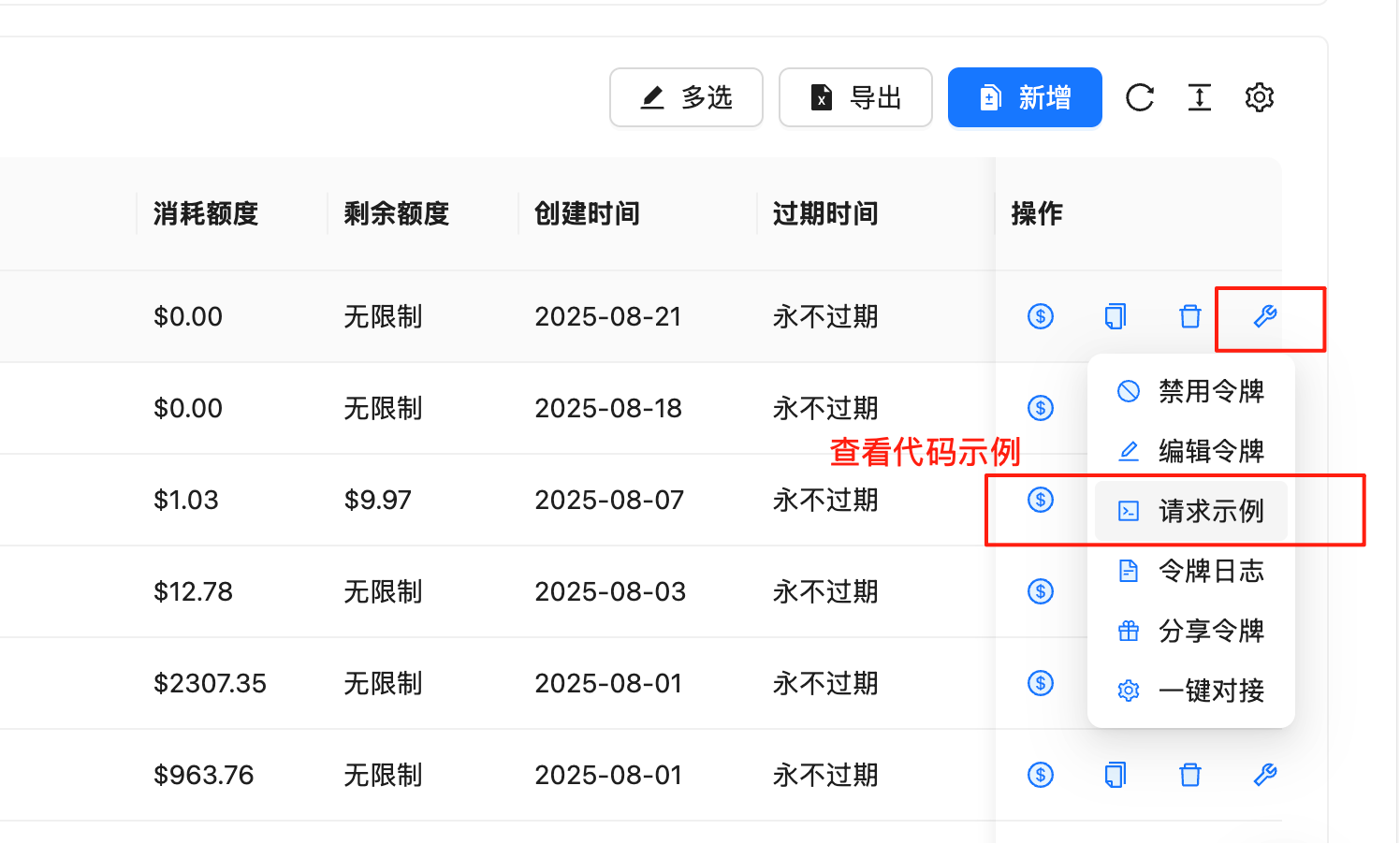
The console has built-in, ready-to-run code examples for many languages, updated in sync with the latest API version — use these first:- Go to the token management page
- On the row of the target API Key, click the 🔧 wrench icon in the “Actions” column
- Select “Request Example” to view complete examples in cURL, Python, Node.js, Java, C#, Go, PHP, Ruby, and more
Online Testing (Playground)
The “API Reference” section provides an online Playground: enter your API Key to send requests and view live responses directly — no code required.Chat Completions
POST /v1/chat/completions — the main chat and multimodal endpoint.List Models
GET /v1/models — query currently available models.Embeddings
POST /v1/embeddings — text vectorization.Playgrounds for image and video generation endpoints live on their respective model pages (see the image / video model page under “Choose a Model” above).
Minimal Example
The most common endpoint — Chat Completions — copy and run. For more parameters and languages, use the Playground above or the console’s “Request Example”:- Python (SDK)
- cURL
Streaming Response
Setstream: true in the request, and the response is returned chunk by chunk as Server-Sent Events (SSE) — ideal for typewriter-style output:
data: , and the final line data: [DONE] signals the end.
Error Handling
Endpoints follow the OpenAI error format:Rate Limits
Exceeding limits returns
429. Please control your request rate accordingly.
Need Help?
Choose a Model
Text / multimodal model recommendations and pricing.
Test Online
Open the API Reference Playground and send requests directly.
- Visit the website: api.apiyi.com
- Technical support email:
support@apiyi.com